PostgreSQL - Architettura e Configurazioni¶
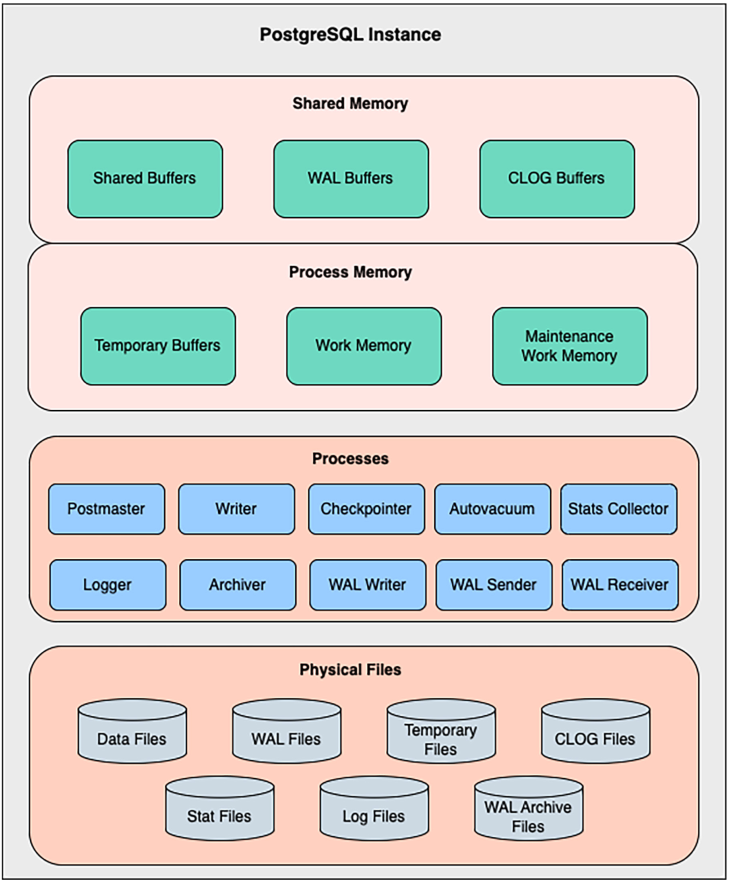
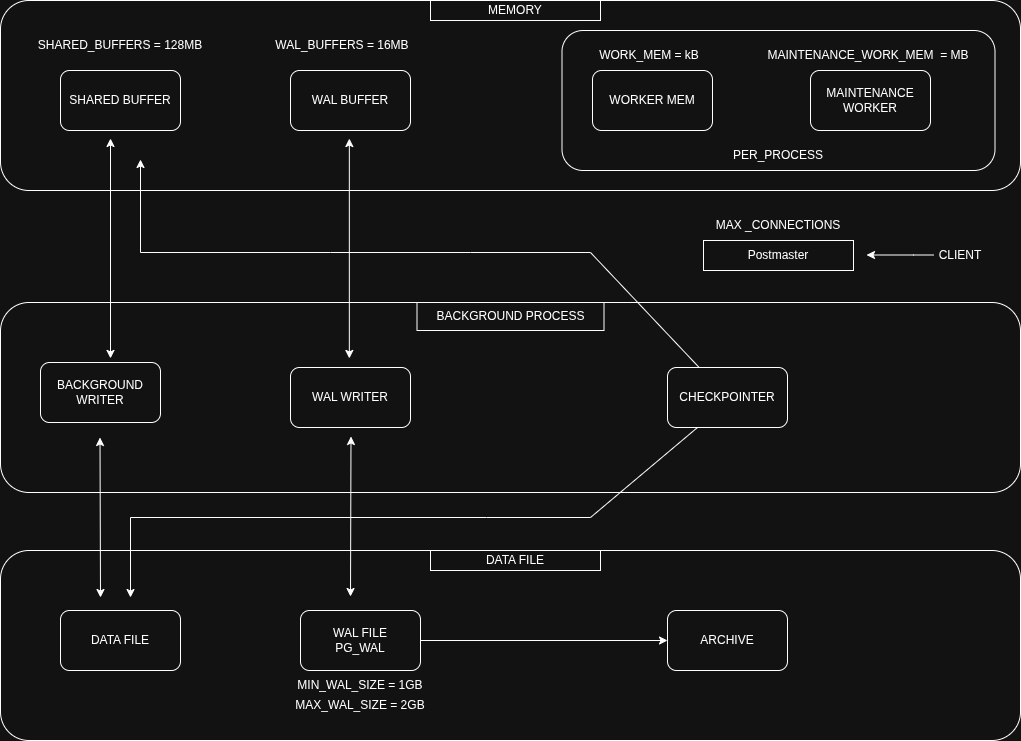
Shared Memory¶
- Buffer Cache : blocchi di dati letti/scritti (tabelle, indici)
- WAL Buffers : log delle transazioni in attesa di scrittura
Parametri consigliati
shared_buffers = 25% RAM(es. 2GB su 8GB) → richiede riavviowal_buffers = 16MB(1/32 dishared_buffers) → modificabile a runtime
shared_buffers: 128MB
wal_buffers: -1
shared_buffers: 2GB
wal_buffers: 16MB
Memory Process¶
- Temporary Buffers : tabelle temporanee della sessione utente
- Work Memory : sort (
ORDER BY,DISTINCT) e hash (join, aggregation) - Maintenance Work Memory : operazioni di manutenzione (
VACUUM,CREATE INDEX, FK)
Parametri consigliati
temp_buffers = 8MB→ modificabile a runtimework_mem = 4MB→ modificabile a runtime, consigliato 25% RAM / max_connectionsmaintenance_work_mem = 64MB→ modificabile a runtime, consigliato 5%-10% RAM
Processi PostgreSQL¶
- Postmaster : processo principale
- Backend Process : uno per ogni connessione client
- WAL Writer : scrive i WAL su disco
- WAL Sender : invia WAL ai replica (replica streaming)
- Background Writer : svuota periodicamente i buffer
- Checkpointer : gestisce i checkpoint
- Autovacuum : pulisce tuple obsolete
- Archiver : opzionale, salva WAL per backup
- Stats Collector : raccoglie metriche di sistema
- Logical Replication : gestisce replica logica
- Startup Process : attivo all’avvio o recovery
- Logger : scrive log di sistema
Parametri consigliati
max_connections = 100→ riavvio richiestoautovacuum = on→ runtimeautovacuum_max_workers = 3→ runtimeautovacuum_naptime = 60s→ runtimewal_writer_delay = 200ms→ runtimebgwriter_delay = 200ms→ runtimecheckpoint_timeout = 5min→ runtimelogging_collector = on→ riavvio richiesto
Physical Files¶
- Data Files : dati di tabelle e indici, pagine da 8KB
- WAL : log transazioni per durabilità e recovery
- WAL Archive : archiviazione WAL per backup/replica
- Control Files : stato e configurazione cluster
- Configuration Files :
postgresql.conf,pg_hba.conf, ecc. - Temporary Files : operazioni temporanee se memoria insufficiente
Parametri consigliati
data_directory→ solo riavviowal_level = replica/minimal→ runtime, alcuni livelli richiedono riavvioarchive_mode = on/off→ riavvioarchive_command→ runtimetemp_file_limit→ runtime
Parallelism¶
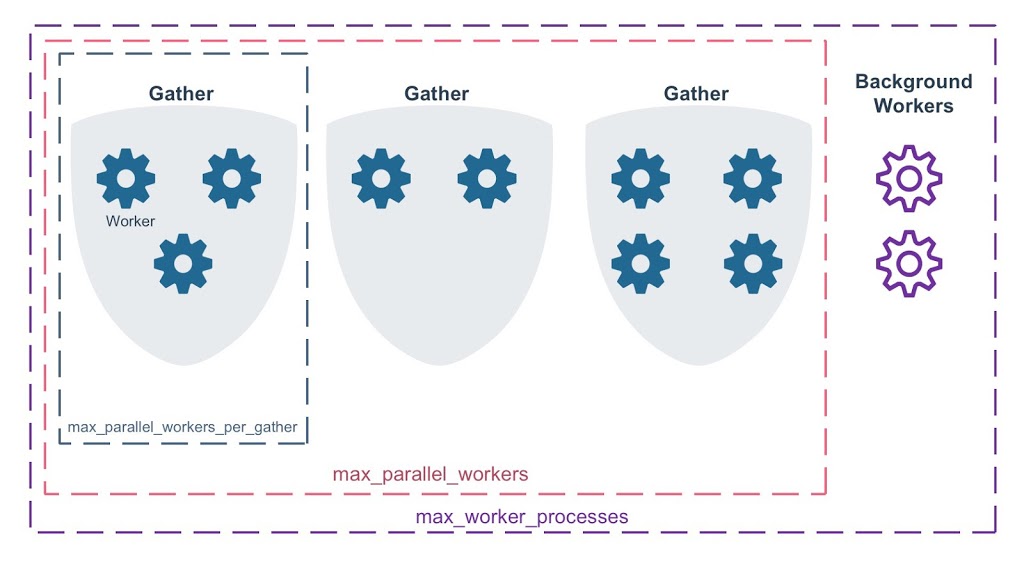
| Parametro | Descrizione |
|---|---|
max_worker_processes |
Max processi worker totali (background, replica, parallelismo) |
max_parallel_workers |
Max worker paralleli complessivi per il server |
max_parallel_workers_per_gather |
Max worker per singola operazione parallela (Gather) |
Esempio configurazione
- 16 core, 4 query parallele simultanee con 3 worker ciascuna
max_worker_processes = 16max_parallel_workers = 12(4 query × 3 worker)max_parallel_workers_per_gather = 3
Così non superi i core disponibili.